Envoy is a powerful open-source modern HTTP proxy server. It doesn't just serve as a proxy; it’s also a swiss army knife widely used in current cloud infrastructure, thanks to the extensible filter design. The best part of Envoy's filter is that you can define your own filtering, routing and transformation logic easily with Lua or WASM and plug them into the Envoy server to achieve things that cannot be done with the built-in filters.
As leaders in the zero data business, we at Very Good Security have been evaluating Envoy to protect incoming and outgoing data for our customers. One straightforward idea is to leverage Envoy by creating a WASM filter which will make gRPC call with the request data to VGS’ internal vault and transform the ingress or egress payload accordingly based on gRPC server's response.
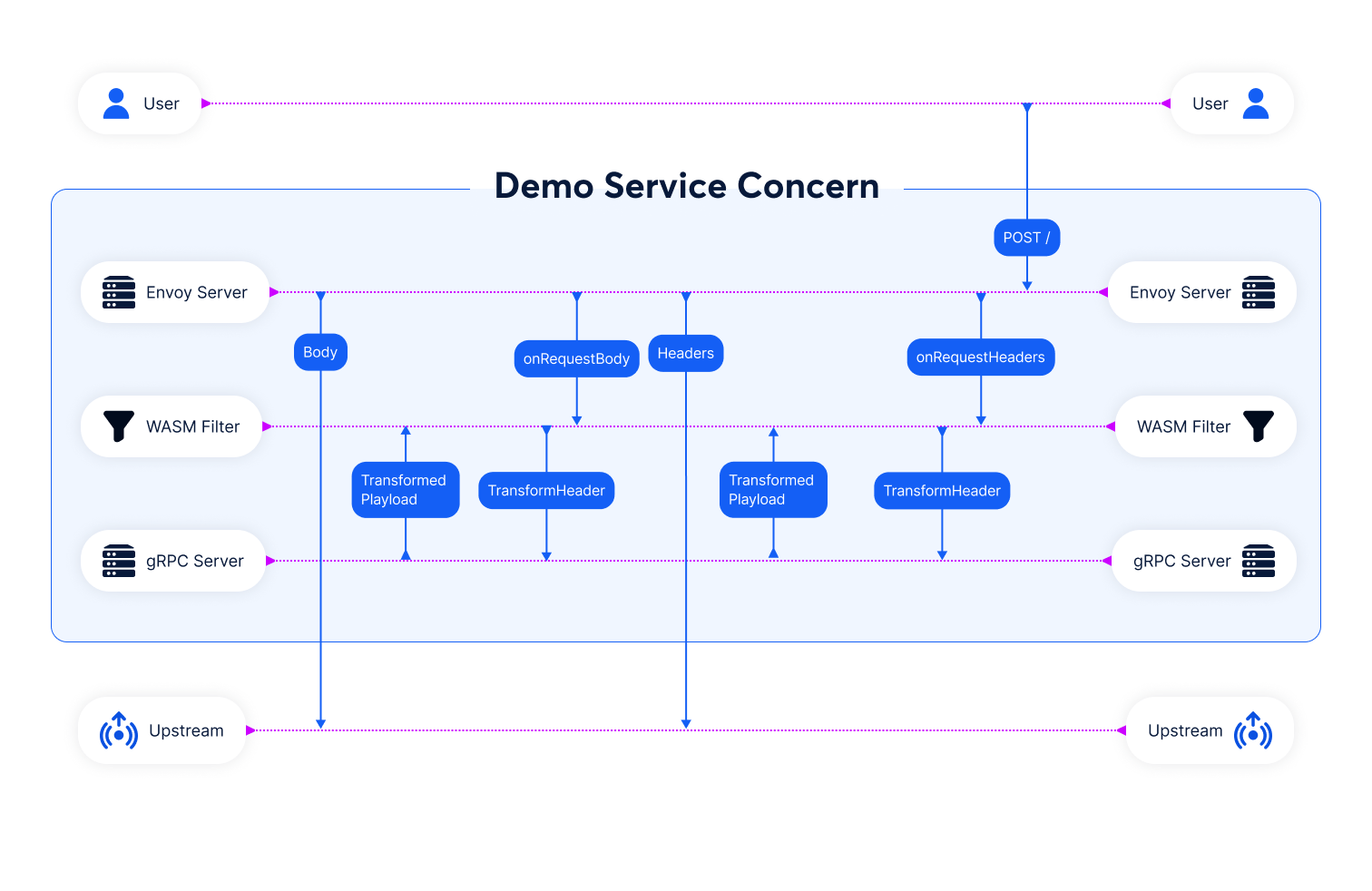
Image: Request flows to envoy, and how the wasm filter makes grpc call for data transformation.
While Envoy is open source and very extensible, the WASM filter as a fairly new feature lacks documentation or examples that show you how to use it. Today, I would like to share a working demo project and our experience with it.
Demo
Before we jump into technical details, let's take a look at the demo project first here:
https://github.com/verygoodsecurity/envoy-grpc-wasm-filter-demo
To try it out yourself, you need to clone it first. As long as you have docker-compose installed on your machine, it should work just out-of-box. Now run
docker-compose up
It takes a while to build the docker containers and will spin up the servers shortly. After the servers are up and running, now you can send out an http request like this:
curl localhost:8000 -d foo=bar -H "x-change-me: value"
And you should see result like this:
{
"path": "/",
"headers": {
"host": "localhost:8000",
"user-agent": "curl/7.58.0",
"accept": "*/*",
"content-type": "application/x-www-form-urlencoded",
"x-forwarded-proto": "http",
"x-request-id": "7d595ccc-4605-44e7-b52a-295d7b48a054",
"x-change-me": "modified value",
"x-new-header": "whatsup",
"x-envoy-expected-rq-timeout-ms": "15000",
"transfer-encoding": "chunked"
},
"method": "POST",
"body": "eggs=bar",
"fresh": false,
"hostname": "localhost",
"ip": "::ffff:192.168.144.4",
"ips": [],
"protocol": "http",
"query": {},
"subdomains": [],
"xhr": false,
"os": {
"hostname": "19e2738c01d9"
}
}
This is a JSON payload containing the HTTP request received by the upstream web server. As you can see, the header x-change-me's value value has been modified by our WASM filter based on the gRPC server's response. Before sending to the web server, it becomes modified value. You can also see the body value was changed from foo=bar to eggs=bar, since we are replacing all foo with eggs.
Make our gPRC service
To demonstrate how to change the request payload via making a call to gRPC service, we made a simple gRPC service like this:
syntax = "proto3";
// The service for transforming http request
service Transform {
rpc TransformHeader (HeaderRequest) returns (HeaderResponse) {}
rpc TransformBody (BodyRequest) returns (BodyResponse) {}
}
// The request header
message RequestHeaderItem {
string key = 1;
string value = 2;
}
// The http request for header
message HeaderRequest {
string path = 1;
repeated RequestHeaderItem headers = 2;
}
// The http response for header
message HeaderResponse {
string path = 1;
repeated RequestHeaderItem headers = 2;
}
// The http request for body
message BodyRequest {
string content = 1;
}
// The http response for body
message BodyResponse {
string content = 1;
}
Basically there are two major functions in the service, the TransformHeader one is for transforming headers, and TransformBody is for transforming body. As this is for demonstration purposes only, we tried our best to keep it as simple as possible without adding too much in it. The TransformHeader takes the request headers as the input and returns a set of headers key value pairs to be added or changed for the incoming request if it desires to transform it. The TransformBody takes the incoming request body as the input and returns content to replace the request's body before sending it to the upstream server.
We already have the C++ and Python files generated from the protobuf file in the demo project at:
- build/transform.pb.cc
- build/transform_pb.h
- build/transform_pb2.py
- build/transform_pb2_grpc.py
But in case if you want to modify the protobuf file and regenerate those files, you can run
docker-compose run make-cpp-grpc
and
docker-compose run make-py-grpc
Building a WASM filter
Now we've already seen how the WASM filter demo works, let's see how to build it. First thing to know is that the WASM filter we are building is against a ABI (Application Binary Interface) spec defined by proxy-wasm/spec project. Originally, the proxy-wasm was part of Envoy but later on was spun off as a standalone project.
Given a well-defined set of ABI, it means different http proxy servers can run the same WASM filter without modification of code as long as they comply with the same standard. Since our demo project is written in C++, we need to install C++ SDK for proxy-wasm in order to be able to build it. You need to clone the sdk project from here:
https://github.com/proxy-wasm/proxy-wasm-cpp-sdk
Then cd into the folder and run:
docker build -t wasmsdk:v2 -f Dockerfile-sdk .
With the SDK docker image ready, the next thing you need is a Makefile. Based on the README document of proxy-wasm-cpp-sdk, the next step is toadd a Makefile with content like this:
PROXY_WASM_CPP_SDK=/sdk
all: myproject.wasm
include ${PROXY_WASM_CPP_SDK}/Makefile.base_lite
We did this, but saw a missing symbols error when compiled. It turned out the protobuf library linked by Makefile.base_lite is against libprotobuf-lite.a. Linking against libprotobuf.a is needed. An alternative is to link Makefile.base against libprotobuf.a. However, as we also need to compile the generated gRPC files, we just modified our version of Makefile directly instead.
Transform request header
Now, let's look at how we handle the incoming request with our WASM filter here. As you can see, at very first, we have a gRPC service object defined here:
GrpcService grpc_service;
grpc_service.mutable_envoy_grpc()->set_cluster_name("grpc");
std::string grpc_service_string;
grpc_service.SerializeToString(&grpc_service_string);
The GrpcService class is actually a generated protobuf class defined here. There are different ways to define how you want to make your gRPC connection. The EnvoyGrpc approach is to delegate the connection to an upstream Envoy cluster defined in the Envoy configuration file. In this way, it's very flexible to change it without touching the WASM filter code. In fact, if you want to pass configuration from Envoy's configuration file into your WASM filter, you can leverage the configuration value defined here. Then use the onConfigure handler function to parse the config values.
bool TransformRootContext::onConfigure(size_t config_size) {
LOG_TRACE("onConfigure");
const WasmDataPtr configuration = getBufferBytes(
WasmBufferType::PluginConfiguration,
0,
config_size
);
// Do you configuration here
return true;
}
In the name of simplicity, we hardwired it to use an Envoy cluster named grpc. Then in the Envoy config file, we wrote:
clusters:
# ...
- name: grpc
type: strict_dns
lb_policy: round_robin
# This is needed as our local gRPC server doesn't support HTTP2 protocol
http2_protocol_options: {}
load_assignment:
cluster_name: grpc
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: grpc
port_value: 8888
Next is making the request protobuf payload object:
HeaderRequest request;
request.set_path(std::string(path->view()).c_str());
auto res = removeRequestHeader("content-length");
if (res != WasmResult::Ok) {
LOG_ERROR("Remove header failed: " + toString(res));
} else {
LOG_ERROR("Remove header ok: " + toString(res));
}
auto result = getRequestHeaderPairs();
auto pairs = result->pairs();
LOG_TRACE(std::string("headers: ") + std::to_string(pairs.size()));
for (auto &p : pairs) {
LOG_TRACE(std::string(p.first) + std::string(" -> ") +
std::string(p.second));
RequestHeaderItem *item = request.add_headers();
item->set_key(std::string(p.first));
item->set_value(std::string(p.second));
}
As it's possible that the body length could change due to the size of content returned from gRPC service for the body is different from the original body, we call removeRequestHeader to remove the content-length from request header here:
auto res = removeRequestHeader("content-length");
With the content-length header removed, GrpcService and request argument ready, we can now call the grpcCallHandler function:
HeaderStringPairs initial_metadata;
std::string requestPayload = request.SerializeAsString();
res = root()->grpcCallHandler(
grpc_service_string, "Transform", "TransformHeader", initial_metadata,
requestPayload, 1000,
std::unique_ptr<GrpcCallHandlerBase>(
new TransformGrpcCallHandler(this, true)));
As you may notice that we are making the protobuf object a string with SerializeAsString before making the call, because that's how grpcCallHandler was defined. It takes serialized string values for the GrpcService object and the request payload. We make a new instance of TransformGrpcCallHandler class and bind this pointer to it, set the header value to true indicating this gRPC request is for transforming header instead of body.
Finally, we return StopAllIterationAndBuffer to tell the Envoy proxy to stop processing this request further in the iteration of filters, buffer the data and wait for further instruction.
return FilterHeadersStatus::StopAllIterationAndBuffer;
This step is critical since if FilterHeadersStatus::Continue is returned, the processing of the request will continue and headers could be processed by the next filter. At that point, we won't be able to change it anymore since the next filter could send it out to the upstream server already.
Return header transform response from gRPC server
Our gRPC server written in python for transforming headers is very simple:
def TransformHeader(self, request, context):
logger = logging.getLogger(__name__)
logger.info("Get header request %s", request)
response = transform_pb2.HeaderResponse(path=request.path)
for item in request.headers:
if item.key == "x-change-me":
header = response.headers.add()
header.key = item.key
header.value = f"modified {item.value}"
logger.info("Modify header %s => %s", item.key, header.value)
header = response.headers.add()
header.key = "x-new-header"
header.value = "whatsup"
return response
It simply looks for x-change-me header key, and will add modified prefix to the header value if found. It also added a new x-new-header.
Upon receiving the response from gRPC server, our gRPC handler first reads the response payload:
WasmDataPtr response_data =
getBufferBytes(WasmBufferType::GrpcReceiveBuffer, 0, body_size);
_transformContext->setEffectiveContext();
It also calls _transformContext->setEffectiveContext function. This step is also important, as it makes the original request context the effective one, otherwise the later continueRequest call may not work.
Then, we process the response payload, change and replace headers accordingly by calling addRequestHeader and replaceRequestHeader here:
const HeaderResponse &response = response_data->proto<HeaderResponse>();
LOG_INFO("Get header resp size: " + toString(response.headers_size()));
for (size_t i = 0; i < response.headers_size(); ++i) {
RequestHeaderItem item = response.headers(i);
if (!getRequestHeader(":method")) {
LOG_INFO("Add header " + item.key() + " => " + item.value());
auto res = addRequestHeader(item.key(), item.value());
if (res == WasmResult::Ok) {
LOG_TRACE("Add header ok: " + toString(res));
} else {
LOG_ERROR("Add header failed: " + toString(res));
}
} else {
LOG_INFO("Replace header " + item.key() + " => " +
item.value());
auto res = replaceRequestHeader(item.key(), item.value());
if (res == WasmResult::Ok) {
LOG_TRACE("Replace header ok: " + toString(res));
} else {
LOG_ERROR("Replace header failed: " + toString(res));
}
}
}
After the transformation to the incoming request is done, we can then call continueRequest function here to let Envoy proxy knows that we are ready and please continue processing the request here:
auto res = continueRequest();
As a result, the request with modified headers will be sent out to the upstream server.
Transform request body
Similarly, to transform the body, we implement onRequestBody handler function. At the very start, we read the buffer of request body:
auto body =
getBufferBytes(WasmBufferType::HttpRequestBody, 0, body_buffer_length);
std::string bodyStr(body->view());
Likewise, we create a GrpcService object
GrpcService grpc_service;
grpc_service.mutable_envoy_grpc()->set_cluster_name("grpc");
std::string grpc_service_string;
grpc_service.SerializeToString(&grpc_service_string);
Then set the BodyRequest content value:
BodyRequest request;
request.set_content(bodyStr);
And make a gRPC call like what we did with the header request but for body instead:
HeaderStringPairs initial_metadata;
std::string requestPayload = request.SerializeAsString();
auto res = root()->grpcCallHandler(
grpc_service_string, "Transform", "TransformBody", initial_metadata,
requestPayload, 1000,
std::unique_ptr<GrpcCallHandlerBase>(
new TransformGrpcCallHandler(this, false)));
Finally, we return:
return FilterDataStatus::StopIterationAndBuffer;
To tell the Envoy server to stop processing the request, buffer the data and wait for our further instruction as well.
Return body transform response from gRPC server
In the Python gRPC server, we simply replace the keyword foo with eggs and return the response to WASM filter:
def TransformBody(self, request, context):
logger = logging.getLogger(__name__)
logger.info("Get body request %s", request)
return transform_pb2.BodyResponse(content=request.content.replace("foo", "eggs"))
Then in the onSuccess function of TransformGrpcCallHandler, the setEffectiveContext function is called to make our request context the effective one:
_transformContext->setEffectiveContext();
Then we take the new content from the Python gRPC server and overwrite the outgoing body buffer for our request to the upstream server here. The way setBuffer works is like assigning a piece Python's string to a slice:
s[str:end] = "replacement"
Unfortunately, this entire process was determined using trial and error and by reading the source code, since we could not find documentation for this anywhere.Because overwriting the original request body buffer requires knowing the original length, we get it first by calling getBufferStatus function:
size_t size;
uint32_t flags;
auto res =
getBufferStatus(WasmBufferType::HttpRequestBody, &size, &flags);
Then you can overwrite the buffer content by:
res = setBuffer(WasmBufferType::HttpRequestBody, 0, size, response.content());
Finally, call continueRequest to tell Envoy server to continue processing the request:
auto res = continueRequest();
And that’s how you can build and compile a WASM filter in Envoy proxy to call a stand-alone gRPC server to transform a HTTP request. While this technology was not a suitable solution for VGS to move its Zero Data platform inside of it has yielded some interesting findings and we look forward to incorporating these learnings into our platform in the future.
If you find this kind of research interesting we’d love to hear from you.
Thank you for reading.




